Python: Web Scraping
17 June 2023, Carlos Pena
In this post, we will visit a page and extract relevant information. for instance we want to automatically obtain stock characteristics and indicators (price, profit, P/V, …).
For this, we chose the website investidor10 which contains information on BR stocks, the website follows the following rule:
https://investidor10.com.br/acoes/[stock-name]/
We start from the premise that the site contains all the necessary information, and the patten must be maintained for all stocks. And so, we can skip the Crawler step (future post).
Download
- Some websites rejects requests without User-Agent
- Respect the robots.txt and do not DDOS!
import requests
headers = {'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_14_5) AppleWebKit/605.1.15 (KHTML, like Gecko) Safari/605.1.15'}
stock_name = "b3sa3"
req = requests.get(f'https://investidor10.com.br/acoes/{stock_name}', headers=headers)
- Check if everything worked (aka 200):
req.status_code == 200
Parser
Once downloaded there are several ways to extract information, such as pandas.read_html, bs4.BeautifulSoup, however, we will use lxml.html.fromstring, and select the information according to its xpath.
tree = html.fromstring(req.content)
XPath
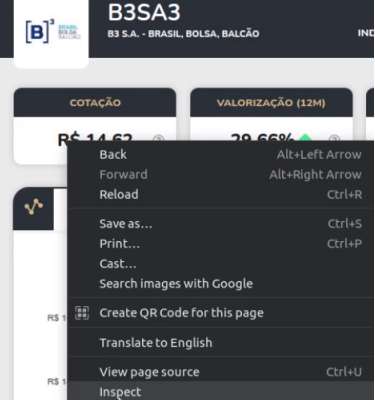
With the help of your browser, access the URL, right-click on the field you want to get its value, and inspect.
This will open a tab of its HTML elements, right-click on the desired information Copy > Copy XPath (or full XPath)
 |
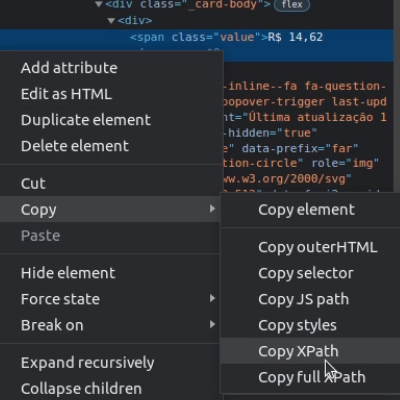 |
Full Xpath: /html/body/div[3]/div/main/section/div/section[1]/div[1]/div[2]/div/span
XPath: //*[@id="cards-ticker"]/div[1]/div[2]/div/span
In this case, as we only want the text field, we can add /text() at the end of the path, and use the xpath method from the tree object.
xpath = r'//*[@id="cards-ticker"]/div[1]/div[2]/div/span/text()'
tree.xpath(xpath)
>>> ['R$ 14,62']
With this, we were able to obtain the desired information.
Depending on the structure of the xpath we can iterate over the div and get even more information, although for tabular data pandas.read_html is a better option.