DB: NoSQL MongoDB: TL;DR
04 July 2024, Carlos Pena
- Motto: Data that is accessed together should be stored together
SQL vs NoSQL
| RDBMS | MongoDB |
| ------ | -------------------------- |
| Table | Collection |
| Row | Document |
| Column | Field |
| Join | Embedding/Linking($Lookup) |
Docker
docker pull mongodb/mongodb-community-server:latest
docker run -p 27017:27017 -d mongodb/mongodb-community-server:latest [--replSet myReplicaSet]
MongoSH
mongosh –port 27017
use mydatabase
db.createCollection("mycollection")
db.mycollection.insertOne({ name: "Carlos Pena", age: 28, occupation: "Engineer" })
db.mycollection.insertMany([
{ name: "Alfa", age: 25, occupation: "Designer" },
{ name: "Bravo", age: 30, occupation: "Manager" }
])
db.mycollection.find({ name: "Carlos Pena" }).pretty()
PyMongo
import random
import pymongo
from pymongo import MongoClient
client = MongoClient("localhost", 27017) # docker default
db = client["my_database"]
Create/Drop Table
collection = db["my_table"] # table -> collection
db.drop_collection("my_table")
Insert
collection.insert_one({"name": "Carlos Pena", "age": 28, "occupation": "Engineer"})
collection.insert_many(
[
{"name": f"A {idx}", "age": random.randint(0, 10_000), "occupation": "Designer"}
for idx in range(1_000_000)
]
)
Update/Replace
collection.insert_one({"name": "Carlos Pena", "age": 28, "occupation": "Engineer"})
collection.update_one(
{"name": "Carlos Pena"}, {"$set": {"age": 99, "occupation": "Data Engineer"}}
)
collection.update_many(
{"name": "Carlos Pena"}, {"$set": {"age": 99, "occupation": "Data Engineer"}}
)
collection.replace_one(
{"name": "Carlos Pena"}, {"name": "Carlos Pena Doe", "age": 0, "occupation": "Engineer"}
)
Delete
collection.delete_one({"name": "Carlos Pena"}) # Check output n
# DeleteResult({'n': 1, 'ok': 1.0}, acknowledged=True) ## Done
# DeleteResult({'n': 0, 'ok': 1.0}, acknowledged=True) ## Not found
collection.delete_many({"name": "Carlos Pena"})
collection.delete_many({"age": {"$lt": 18}})
Query
for doc in collection.find({"name": "Carlos Pena"}):
print(doc)
for doc in collection.find({"age": {"$lt": 2}}):
print(doc)
Index
collection.create_index({"age": pymongo.ASCENDING}) # returns index name
# Index Types: pymongo.ASCENDING, pymongo.DESCENDING, pymongo.GEO2D, pymongo.GEOSPHERE
# pymongo.HASHED, pymongo.TEXT
# Main parameters:
# - `unique`: if ``True``, creates a uniqueness constraint on the index.
# - `background`: if ``True``, this index should be created in the background.
collection.drop_index("age_1")
# Perf: %%timeit
for _ in collection.find({"age": {"$eq": 10_000}}):
pass
# WO Index: 260 ms ± 01.3 ms per loop (mean ± std. dev. of 7 runs, 1 loop each)
# W Index: 232 μs ± 14.6 μs per loop (mean ± std. dev. of 7 runs, 1,000 loops each)
Text Search
# Setup
import random
import string
import pymongo
from pymongo import MongoClient
# Data
client = MongoClient("localhost", 27017)
db = client["mydatabase"]
collection = db["text_search_collection"]
collection.insert_many(
[
{
"first_name": "".join(random.sample(string.ascii_letters, k=10)),
"last_name": "".join(random.sample(string.ascii_letters, k=10)),
"age": random.randint(0, 100),
}
for _ in range(1_000_000)
]
)
Text Index
collection.create_index({"first_name": pymongo.TEXT})
# Text search only works using the $text query operator.
# Warning: One Text Index Per Collection
for doc in collection.find({"first_name": {"$regex": "^AabB.*"}}): # or "^AabB"
print(doc)
# Wo Index: 442 ms ± 6.41 ms per loop (mean ± std. dev. of 7 runs, 1 loop each)
# W Index: 294 μs ± 29.9 μs per loop (mean ± std. dev. of 7 runs, 1,000 loops each)
for doc in collection.find({"first_name": {"$regex": ".*AabB.*"}}): # or "AabB"
print(doc)
# W/Wo Index: 442 ms ± 6.41 ms per loop (mean ± std. dev. of 7 runs, 1 loop each)
# Cannot use index if prefix is unknown
# Regex case insensitive
collection.create_index({"first_name": pymongo.ASCENDING, "strength": 2})
# Case-insensitive indexes typically *do not* improve performance for $regex queries
for doc in collection.find({"first_name": {"$regex": "^AabB", "$options": "i"}}):
print(doc)
# Wo Index: 433 ms ± 8.69 ms per loop (mean ± std. dev. of 7 runs, 1 loop each)
for doc in collection.find({"first_name": "bgGDTVwJnm"}):
print(doc)
# collection.create_index({"first_name": pymongo.TEXT})
# Wo Index: 289 ms ± 1.6 ms per loop (mean ± std. dev. of 7 runs, 1 loop each)
# W Index: 290 ms ± 2.3 ms per loop (mean ± std. dev. of 7 runs, 1 loop each)
# index not used as it is not a $regex; we need to create another index
collection.create_index({"first_name": pymongo.ASCENDING})
# W Index: 269 μs ± 58.3 μs per loop (mean ± std. dev. of 7 runs, 1,000 loops each)
Text Index with multiple fields
collection.create_index({"first_name": pymongo.TEXT, "last_name": pymongo.TEXT})
# Text search only works using the $text query operator.
# Warning: One Text Index Per Collection
collection.insert_many(
[
{
"first_name": "Carlos Henrique",
"last_name": "Pena, Carlos",
"age": 28,
},
{
"first_name": "Carlos Henrique",
"last_name": "Caloete Pena",
"age": 28,
},
{
"first_name": "Henrique",
"last_name": "Pena, Carlos",
"age": 28,
},
]
)
for doc in collection.find({"$text": {"$search": "Carlos"}}):
print(doc)
# 323 μs ± 63.8 μs per loop (mean ± std. dev. of 7 runs, 1,000 loops each)
# Matches the three docs
Embedding vs Referencing Pt 1: Theory
- Embedding:
- Single operation to: retrieve data; Update/delete
- Data duplication; large documents
- Used when data is acessed together frequently
- One-to-One, One-to-Many (when many is small)
- Referencing:
- No duplication; smaller documents
- Require to join data
- Used when data is not always needed when acessing the document:
- many-to-many, one-to-many (when many is large/unbounded)
- You (the code) need to maintain data consistency and avoid redundancy.
Exemple: Products (1) vs (N) Reviews
Embedding “One” Side
{
"SKU": 4000,
"Title": "Digital Microwave Oven 220v",
"Price": 102.00,
"reviews": [
{"user": "Carlos", "text": "Ok."},
{"user": "Henrique", "text": "Not good"},
{"user": "Gabriel", "text": "Expensive"},
]
}
Embedding “Many/N” Side
{
"user": "Carlos",
"text": "Ok.",
"product": {
"SKU": 4000,
"Title": "Digital Microwave Oven 220v",
"Price": 102.00,
}
}
{
"user": "Henrique",
"text": "Not good",
"product": {
"SKU": 4000,
"Title": "Digital Microwave Oven 220v",
"Price": 102.00,
}
}
{
"user": "Gabriel",
"text": "Expensive",
"product": {
"SKU": 4000,
"Title": "Digital Microwave Oven 220v",
"Price": 102.00,
}
}
Referencing “One” Side
{
"SKU": 4000,
"Title": "Digital Microwave Oven 220v",
"Price": 102.00,
"reviews": [111, 589, 999]
}
{
"id": 111,
"user": "Carlos",
"text": "Ok."
}
{
"id": 589,
"user": "Henrique",
"text": "Not good"
}
{
"id": 999,
"user": "Gabriel",
"text": "Expensive"
}
Referencing “Many/N” Side
{
"id": 1024,
"SKU": 4000,
"Title": "Digital Microwave Oven 220v",
"Price": 102.00,
}
{
"product_id": 1024,
"user": "Carlos",
"text": "Ok."
}
{
"product_id": 1024,
"user": "Henrique",
"text": "Not good",
}
{
"product_id": 1024,
"user": "Gabriel",
"text": "Expensive",
}
Referencing many-to-many
{
"id": 1024,
"SKU": 4000,
"Title": "Digital Microwave Oven 220v",
"Price": 102.00,
"reviews": [100, 200, 300]
}
{
"id": 100,
"product_id": 1024,
"user": "Carlos",
"text": "Ok."
}
{
"id": 200,
"product_id": 1024,
"user": "Henrique",
"text": "Not good",
}
{
"id": 300,
"product_id": 1024,
"user": "Gabriel",
"text": "Expensive",
}
Embedding vs Referencing Pt 2: Python
Embedding (One side)
catalog = db["catalog"]
products = [
{
"sku": 4,
"title": "Notebook",
"price": 1000.50,
"reviews": [
{
"review_id": 1,
"reviewer": "Alice",
"rating": 5,
"comment": "Great Notebook!",
},
{
"review_id": 2,
"reviewer": "Bob",
"rating": 4,
"comment": "Good value for money.",
},
],
},
{
"sku": 103,
"title": "Smartphone",
"price": 699.00,
"reviews": [
{
"review_id": 3,
"reviewer": "Charlie",
"rating": 4,
"comment": "Very nice phone.",
},
{
"review_id": 4,
"reviewer": "Dave",
"rating": 3,
"comment": "Average battery life.",
},
],
},
]
catalog.insert_many(products)
catalog.find_one({"sku": 4})
# Update new review
new_review = {
"review_id": 5,
"reviewer": "Eve",
"rating": 5,
"comment": "Excellent performance.",
}
catalog.update_one({"sku": 4}, {"$push": {"reviews": new_review}})
# UpdateResult({'n': 1, 'nModified': 1, 'ok': 1.0, 'updatedExisting': True}, acknowledged=True); Updated
# UpdateResult({'n': 0, 'nModified': 0, 'ok': 1.0, 'updatedExisting': False}, acknowledged=True); Not found
# Delete review
catalog.update_one({"sku": 103}, {"$pull": {"reviews": {"review_id": 4}}})
# UpdateResult({'n': 1, 'nModified': 1, 'ok': 1.0, 'updatedExisting': True}, acknowledged=True) # Removed
# UpdateResult({'n': 1, 'nModified': 0, 'ok': 1.0, 'updatedExisting': True}, acknowledged=True) # Product found, but review not
# UpdateResult({'n': 0, 'nModified': 0, 'ok': 1.0, 'updatedExisting': False}, acknowledged=True) # Product not found
Referencing (One side)
db.products.drop()
db.reviews.drop()
catalog = db["catalog"]
reviews = db["reviews"]
products = [
{"sku": 1, "title": "Notebook", "price": 1000.50, "review_ids": [1, 2]},
{"sku": 2, "title": "Smartphone", "price": 699.00, "review_ids": [3, 4]},
]
user_reviews = [
{"_id": 1, "reviewer": "Alice", "rating": 5, "comment": "Great Notebook!"},
{"_id": 2, "reviewer": "Bob", "rating": 4, "comment": "Good value for money."},
{"_id": 3, "reviewer": "Charlie", "rating": 4, "comment": "Very nice phone."},
{"_id": 4, "reviewer": "Dave", "rating": 3, "comment": "Average battery life."},
{"_id": 5, "reviewer": "Eve", "rating": 5, "comment": "Excellent performance."},
]
reviews.insert_many(user_reviews)
catalog.insert_many(products)
# Find reviews of a product
product = catalog.find_one({"sku": 1})
# assert product is not None
reviews.find({"_id": {"$in": product["review_ids"]}})
for r in reviews.find({"_id": {"$in": product["review_ids"]}}):
pprint(r)
# Add new review (update catalog)
new_review = {
"_id": 6,
"reviewer": "Frank",
"rating": 4,
"comment": "Solid build quality.",
}
reviews.insert_one(new_review)
catalog.update_one({"sku": 1}, {"$push": {"review_ids": new_review["_id"]}})
# Delete a review (update catalog)
reviews.delete_one({"_id": 2})
products_with_deleted_review = catalog.find({"review_ids": 2})
for p in products_with_deleted_review:
# If `_id` is not specified, mongodb will generated automatically on insert
r = catalog.update_one({"_id": p["_id"]}, {"$pull": {"review_ids": 2}})
Operations: $lookup, $unwind, …
- $Match
pipeline = [
{
"$match": {
"$or": [
{"price": {"$gt": 10.70, "$lt": 11}},
# Do not exists review_ids[1]; aka len(review_ids) <= 1
{
"$and": [
{"review_ids.1": {"$exists": False}},
{"price": {"$gte": 999.55}},
]
},
]
}
}
]
catalog.aggregate(pipeline)
{ # 10.70 < price < 11
"_id": 1510,
"price": 10.76,
"review_ids": [38904, ..., 67487],
"title": "Universal demand-driven moratorium",
}
{ # 10.70 < price < 11
"_id": 8601,
"price": 10.95,
"review_ids": [20853, ..., 30405],
"title": "Multi-lateral upward-trending moderator",
}
{ # (999.55 <= price) and (len(review_ids) <= 1)
"_id": 3562,
"price": 999.76,
"review_ids": [55444],
"title": "Visionary incremental installation",
}
{ # (999.55 <= price) and (len(review_ids) <= 1)
"_id": 583,
"price": 999.89,
"review_ids": [],
"title": "Quality-focused system-worthy customer loyalty",
}
- $Lookup (left join)
// Syntax
{
$lookup:
{
from: <collection to join>,
localField: <field from the input documents>,
foreignField: <field from the documents of the "from" collection>,
as: <output array field>
}
}
results = catalog.aggregate( # From "catalog c"
[
{"$match": {"price": {"$gt": 10.70, "$lt": 11}}},
{
"$lookup": {
"from": "reviews", # Join "reviews r"
"localField": "review_ids", # On (c.review_ids = r._id)
"foreignField": "_id",
"as": "reviews", # select foo as reviews, c.* (kinda)
}
}
]
)
for result in results:
pprint(result)
{
"_id": ObjectId("6687c337d7dc1ee1b75d15aa"),
"price": 10.75,
"review_ids": [1, 6],
"reviews": [
{"_id": 1, "comment": "Great Notebook!", "rating": 5, "reviewer": "Alice"},
{"_id": 6, "comment": "Solid build quality.", "rating": 4, "reviewer": "Frank"},
],
"sku": 1,
"title": "Notebook",
}
{
...
}
- $Unwind
Deconstructs an array field from the input documents to output a document for each element. Each output document is the input document with the value of the array field replaced by the element.
// From:
{ _id : 1, item : 'Shirt', sizes: ['S', 'M', 'L'] }
// To:
{ _id: 1, item: 'Shirt', sizes: 'S' },
{ _id: 1, item: 'Shirt', sizes: 'M' },
{ _id: 1, item: 'Shirt', sizes: 'L' },
results = catalog.aggregate( # From "catalog c"
[
{"$match": {"price": {"$gt": 10.70, "$lt": 11}}},
{
"$lookup": {
"from": "reviews", # Join "reviews r"
"localField": "review_ids", # On (c.review_ids = r._id)
"foreignField": "_id",
"as": "reviews", # select foo as reviews, c.* (kinda)
}
},
{"$unwind": "$reviews"},
]
)
for result in results:
pprint(result)
{
"_id": ObjectId("6687c337d7dc1ee1b75d15aa"),
"price": 10.75,
"review_ids": [1, 6],
"reviews": {"_id": 6, "comment": "Solid build quality.", "rating": 4, "reviewer": "Frank"},
"sku": 1,
"title": "Notebook",
}
{
"_id": ObjectId("6687c337d7dc1ee1b75d15aa"),
"price": 10.75,
"review_ids": [1, 6],
"reviews": {"_id": 1, "comment": "Great Notebook!", "rating": 5, "reviewer": "Alice"},
"sku": 1,
"title": "Notebook",
}
{
...
}
- $Group
{
$group:
{
_id: <expression>,
<field1>: { <accumulator1> : <expression1> },
...
}
}
// $avg, $bottom, $bottomN, $count, $first, $last,
// $max, $median, $minN, $stdDevPop, $sum, $top, ...
Give a list of products:
- 10.70 < Price < 11.00
- Reviews with rating from 2 to 4
results = catalog.aggregate( # From "catalog c"
[
{"$match": {"price": {"$gt": 10.70, "$lt": 11}}},
{
"$lookup": {
"from": "reviews", # Join "reviews r"
"localField": "review_ids", # On (c.review_ids = r._id)
"foreignField": "_id",
"as": "reviews", # select foo as reviews, c.* (kinda)
}
},
{"$unwind": "$reviews"},
# reviews with score from 2 to 4
{"$match": {"reviews.rating": {"$gte": 2, "$lte": 4}}},
{
"$group": {
"_id": "$_id",
"title": {"$first": "$title"},
"price": {"$first": "$price"},
"review_ids": {"$first": "$review_ids"},
"reviews": {"$push": "$reviews"},
# Average of reviews with score from 2 to 4
"reviews_avg": {"$avg": "$reviews.rating"},
"reviews_count": {"$count": {}},
}
},
]
)
for r in results:
pprint(r)
{
"_id": ObjectId("6687c337d7dc1ee1b75d15aa"),
"price": 10.75,
"review_ids": [1, 6],
"reviews": [{"_id": 6, "comment": "Solid build quality.", "rating": 4, "reviewer": "Frank"}],
"sku": 1,
"title": "Notebook",
"reviews_avg": 4
"reviews_count": 1
}
...
- $sort
{ $sort: { <field1>: <sort order>, <field2>: <sort order> ... } }
Sort results by:
- Score: DESC
- _ID: ASC
results = catalog.aggregate( # From "catalog c"
[
{"$match": {"price": {"$gt": 10.70, "$lt": 11}}},
{
"$lookup": {
"from": "reviews", # Join "reviews r"
"localField": "review_ids", # On (c.review_ids = r._id)
"foreignField": "_id",
"as": "reviews", # select foo as reviews, c.* (kinda)
}
},
{"$unwind": "$reviews"},
{"$sort": {"reviews.rating": -1, "reviews._id": 1}},
{
"$group": {
"_id": "$_id",
"title": {"$first": "$title"},
"price": {"$first": "$price"},
"review_ids": {"$first": "$review_ids"},
"reviews": {"$push": "$reviews"},
# Average of reviews with score from 2 to 4
"reviews_avg": {"$avg": "$reviews.rating"},
"reviews_count": {"$count": {}},
}
},
]
)
...
{
"reviews": [
{
"_id": 31468,
"comment": "Still political newspaper tend those degree " "practice.",
"rating": 5,
"reviewer": "Angela Garcia DVM",
},
{
"_id": 37503,
"comment": "Nearly including reason any throughout rest.",
"rating": 5,
"reviewer": "Wendy Estes",
},
{
"_id": 190,
"comment": "Within ground site start although information sign "
"product hold middle determine.",
"rating": 4,
"reviewer": "Susan Gamble",
},
{
"_id": 18932,
"comment": "Husband through structure glass fill real smile.",
"rating": 4,
"reviewer": "Desiree Ramirez",
},
{
"_id": 25235,
"comment": "Collection music person magazine fill blood similar " "again.",
"rating": 4,
"reviewer": "Jeffrey Yu",
}
...
],
"reviews_avg": 2.6875,
"reviews_count": 16,
"title": "Universal demand-driven moratorium",
}
Explain Plan
# Populate
from random import randint, uniform
from faker import Faker
# Insert reviews in batches to avoid memory issues
batch_size = 1000
num_products = 10000
num_reviews = 100000
fake = Faker()
# Reviews
fake_reviews = []
for i in range(0, num_reviews):
review = {
"_id": i,
"reviewer": fake.name(),
"rating": randint(1, 5),
"comment": fake.sentence(nb_words=10),
}
fake_reviews.append(review)
for i in range(0, len(fake_reviews), batch_size):
reviews.insert_many(fake_reviews[i : i + batch_size])
# Catalog
products = []
for i in range(0, num_products):
num_product_reviews = randint(0, 20)
product_review_ids = [randint(1, num_reviews) for _ in range(num_product_reviews)]
product = {
"_id": i,
"title": fake.catch_phrase(),
"price": round(uniform(10, 1000), 2),
"review_ids": product_review_ids,
}
products.append(product)
for i in range(0, len(products), batch_size):
catalog.insert_many(products[i : i + batch_size])
# Dummy query
catalog.find({"price": {"$lt": 11}}).explain()
| Without Index | With Index |
|---|---|
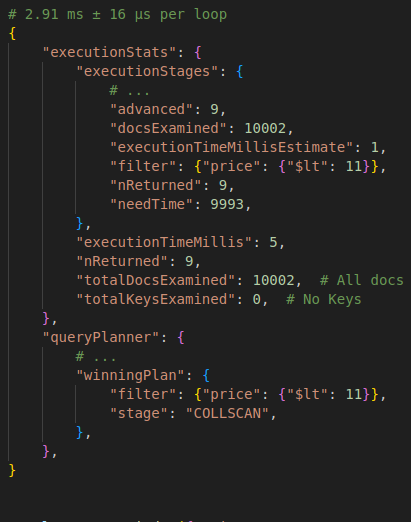 |
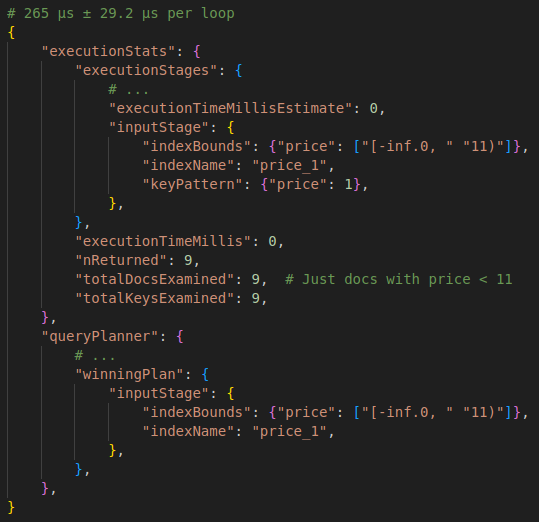 |
- For more complex queries, such as multiple-documents, the “.explain” may fail; In these cases we can use the
pymongoexplainlib
from pymongoexplain import ExplainableCollection
pipeline = [
{
"$lookup": {
"from": "reviews", # "catalog c" (ommited) Join "reviews r"
"localField": "review_ids", # On (c.review_ids = r._id)
"foreignField": "_id",
"as": "reviews", # select foo as reviews, *
}
}
]
pprint(ExplainableCollection(catalog).aggregate(pipeline))